2025
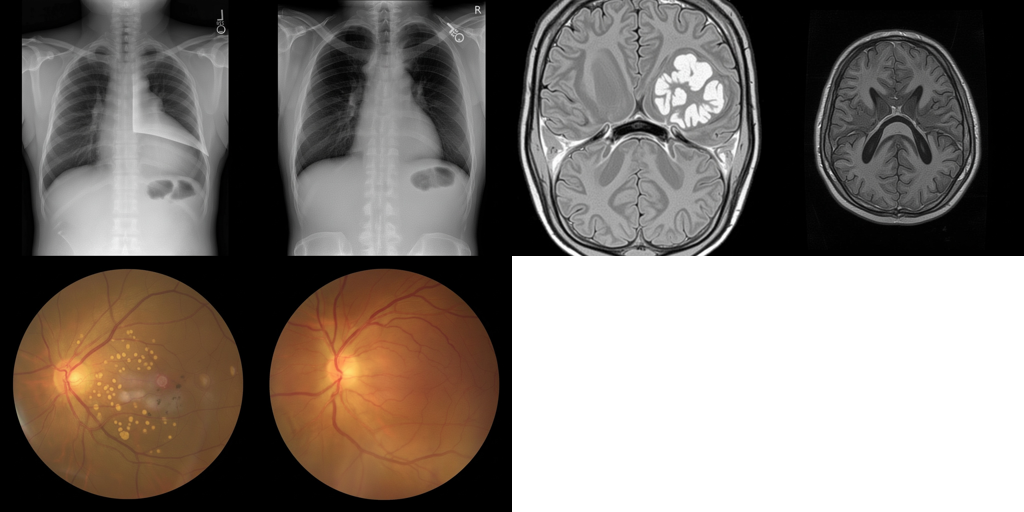
Med-Banana-50K: A Large-Scale Cross-Modality Dataset for Medical Image Editing 🔗
Zhihui Chen, et al.
arXiv preprint 2025
Recent advances in multimodal large language models have enabled remarkable medical image editing capabilities. However, the research community's progress remains constrained by the absence of large-scale, high-quality, and openly accessible datasets built specifically for medical image editing with strict anatomical and clinical constraints. We introduce Med-Banana-50K, a comprehensive 50K-image dataset for instruction-based medical image editing spanning three modalities (chest X-ray, brain MRI, fundus photography) and 23 disease types. Our dataset is constructed by leveraging Gemini-2.5-Flash-Image to generate bidirectional edits (lesion addition and removal) from real medical images. What distinguishes Med-Banana-50K from general-domain editing datasets is our systematic approach to medical quality control: we employ LLM-as-Judge with a medically grounded rubric and history-aware iterative refinement up to five rounds.
Med-Banana-50K: A Large-Scale Cross-Modality Dataset for Medical Image Editing 🔗
Zhihui Chen, et al.
arXiv preprint 2025
Recent advances in multimodal large language models have enabled remarkable medical image editing capabilities. However, the research community's progress remains constrained by the absence of large-scale, high-quality, and openly accessible datasets built specifically for medical image editing with strict anatomical and clinical constraints. We introduce Med-Banana-50K, a comprehensive 50K-image dataset for instruction-based medical image editing spanning three modalities (chest X-ray, brain MRI, fundus photography) and 23 disease types. Our dataset is constructed by leveraging Gemini-2.5-Flash-Image to generate bidirectional edits (lesion addition and removal) from real medical images. What distinguishes Med-Banana-50K from general-domain editing datasets is our systematic approach to medical quality control: we employ LLM-as-Judge with a medically grounded rubric and history-aware iterative refinement up to five rounds.
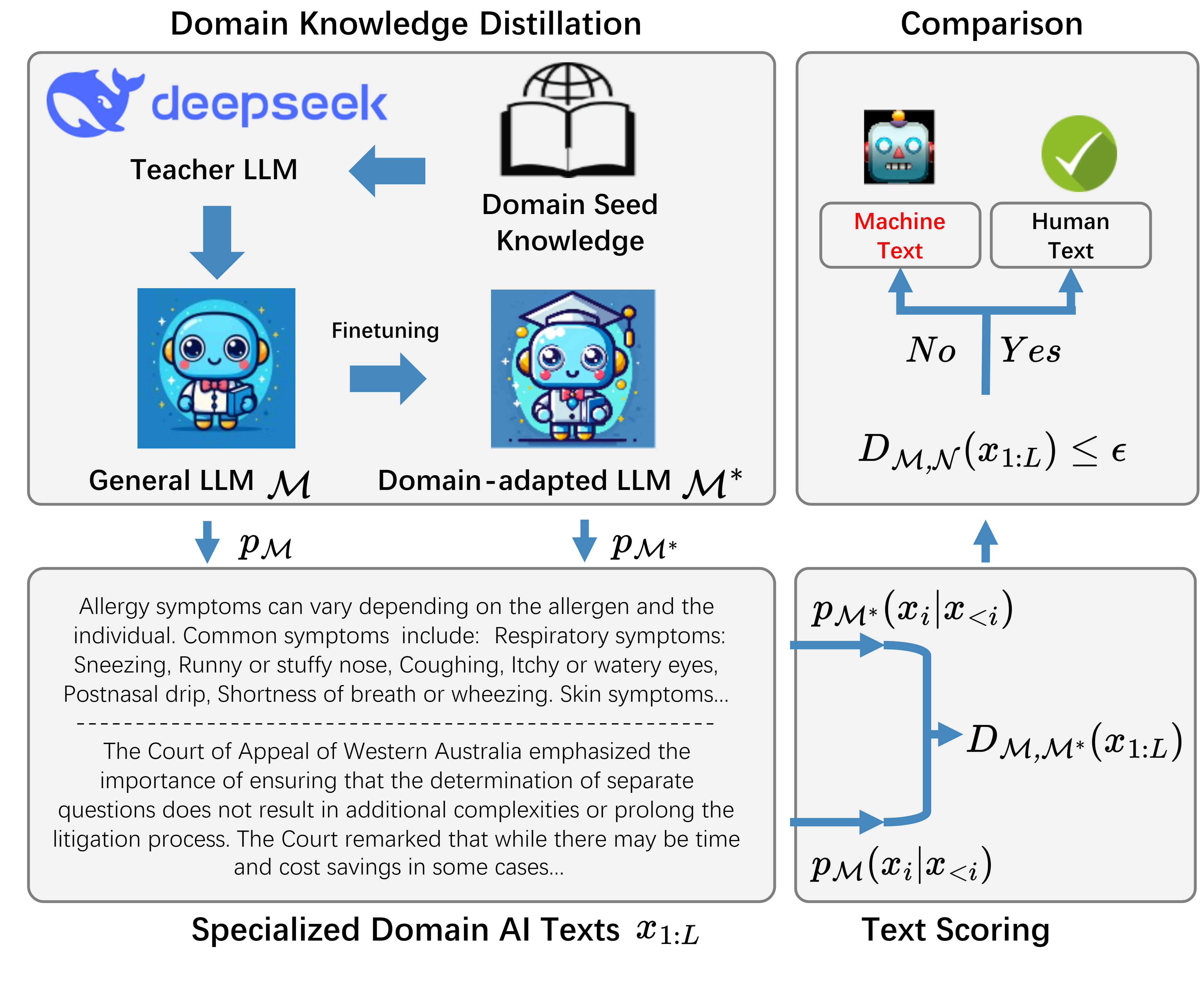
DivScore: Zero-Shot Detection of LLM-Generated Text in Specialized Domains 🔗
Zhihui Chen, Kai He, Yucheng Huang, Yunxiao Zhu, Mengling Feng
Conference on Empirical Methods in Natural Language Processing (EMNLP) 2025 Main Conference" data-zh=" 主会议"> Main Conference
Detecting LLM-generated text in specialized and high-stakes domains like medicine and law is crucial for combating misinformation and ensuring authenticity. We propose DivScore, a zero-shot detection framework using normalized entropy-based scoring and domain knowledge distillation to robustly identify LLM-generated text in specialized domains. Experiments show that DivScore consistently outperforms state-of-the-art detectors, with 14.4% higher AUROC and 64.0% higher recall at 0.1% false positive rate threshold.
DivScore: Zero-Shot Detection of LLM-Generated Text in Specialized Domains 🔗
Zhihui Chen, Kai He, Yucheng Huang, Yunxiao Zhu, Mengling Feng
Conference on Empirical Methods in Natural Language Processing (EMNLP) 2025 Main Conference" data-zh=" 主会议"> Main Conference
Detecting LLM-generated text in specialized and high-stakes domains like medicine and law is crucial for combating misinformation and ensuring authenticity. We propose DivScore, a zero-shot detection framework using normalized entropy-based scoring and domain knowledge distillation to robustly identify LLM-generated text in specialized domains. Experiments show that DivScore consistently outperforms state-of-the-art detectors, with 14.4% higher AUROC and 64.0% higher recall at 0.1% false positive rate threshold.
2024
Production Efficiency Analysis Based on RFID-Collected Manufacturing Big Data
Zhihui Chen
52nd NAMRC (North American Manufacturing Research Conference) 2024
This paper presents a production efficiency analysis framework based on RFID-collected manufacturing big data, enabling real-time monitoring and optimization of manufacturing processes.
Production Efficiency Analysis Based on RFID-Collected Manufacturing Big Data
Zhihui Chen
52nd NAMRC (North American Manufacturing Research Conference) 2024
This paper presents a production efficiency analysis framework based on RFID-collected manufacturing big data, enabling real-time monitoring and optimization of manufacturing processes.
2021
Clustering Enabled Few-Shot Load Forecasting
Qiyuan Wang, Zhihui Chen
IEEE iSPEC (International Smart Power and Energy Conference) 2021
We propose a clustering-enabled few-shot learning approach for load forecasting, which significantly improves prediction accuracy with limited training data. This work also led to a patent (CN113887812B).
Clustering Enabled Few-Shot Load Forecasting
Qiyuan Wang, Zhihui Chen
IEEE iSPEC (International Smart Power and Energy Conference) 2021
We propose a clustering-enabled few-shot learning approach for load forecasting, which significantly improves prediction accuracy with limited training data. This work also led to a patent (CN113887812B).